
|
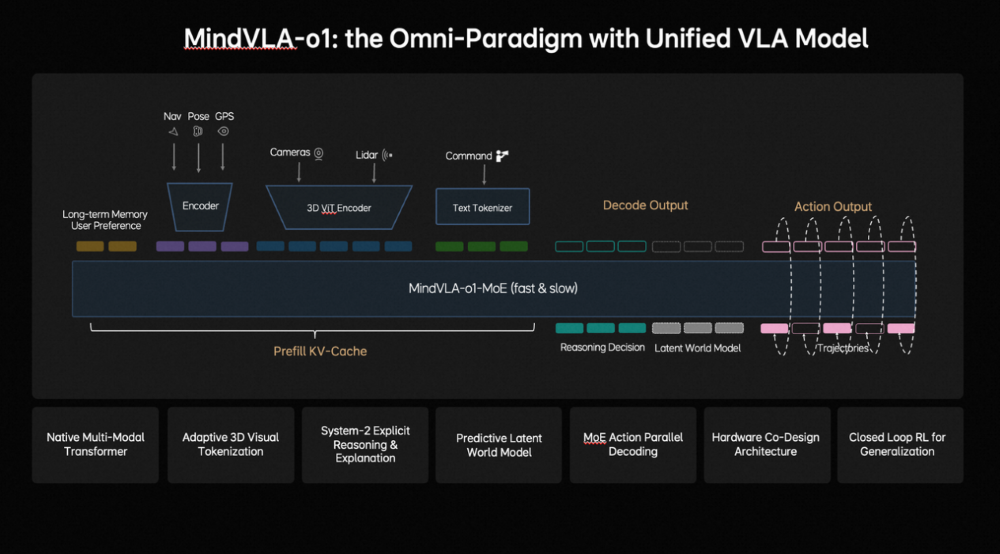
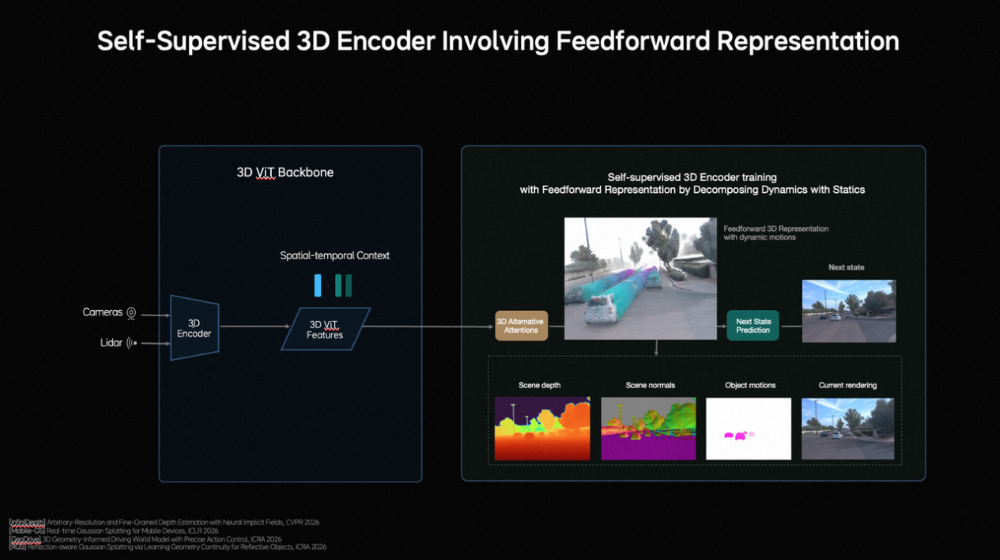
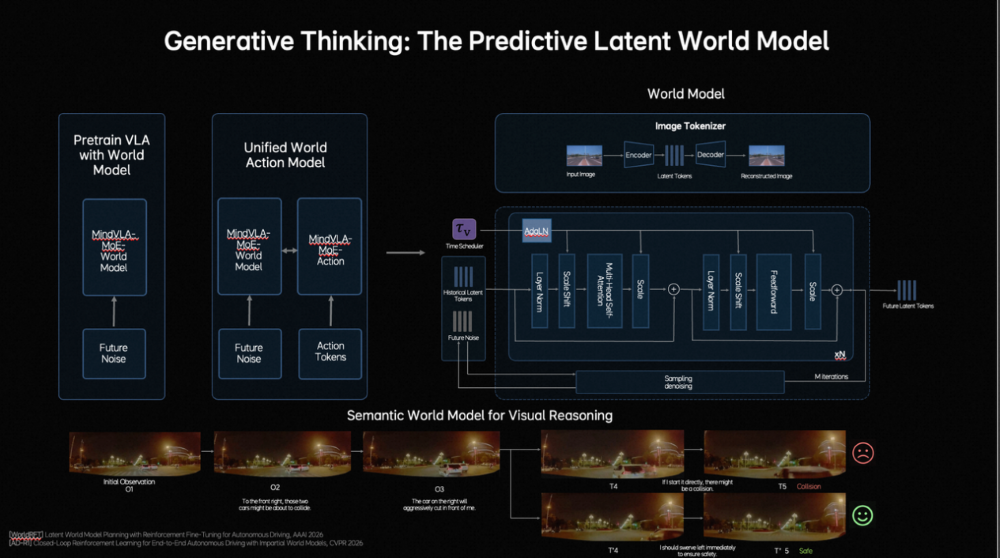
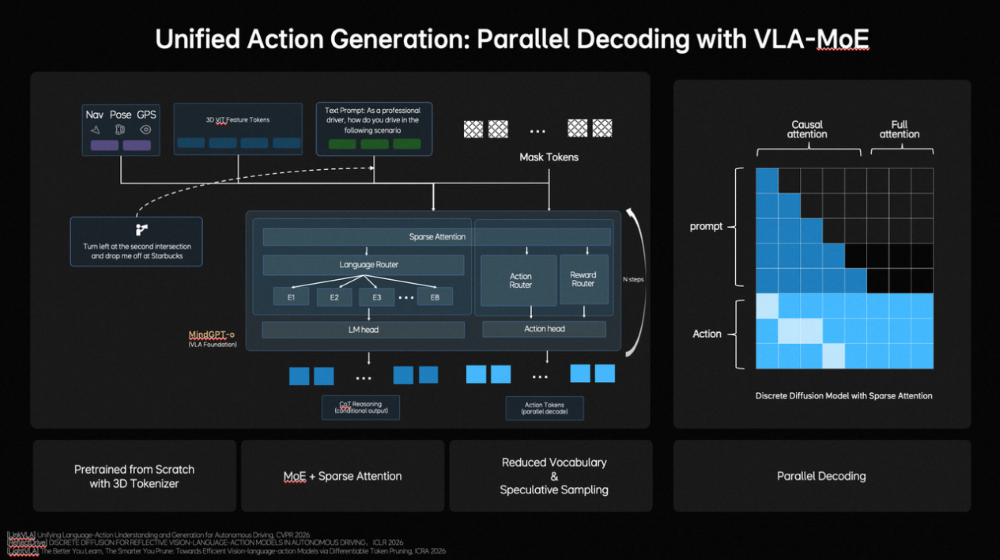
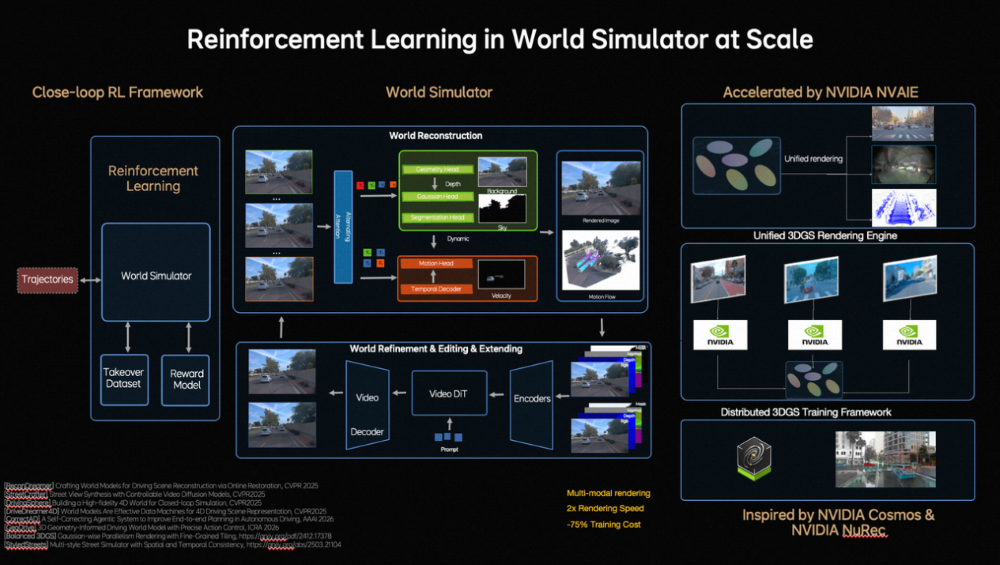
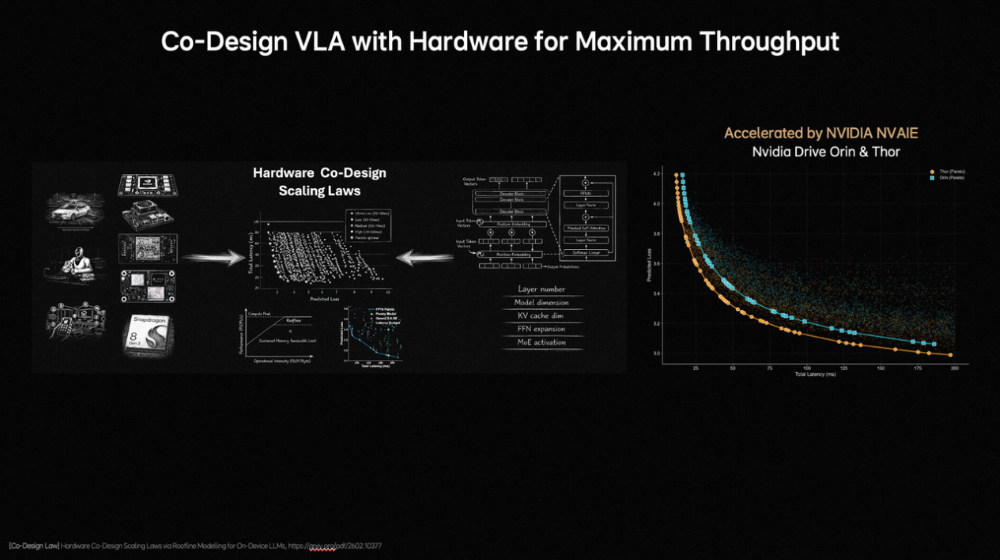
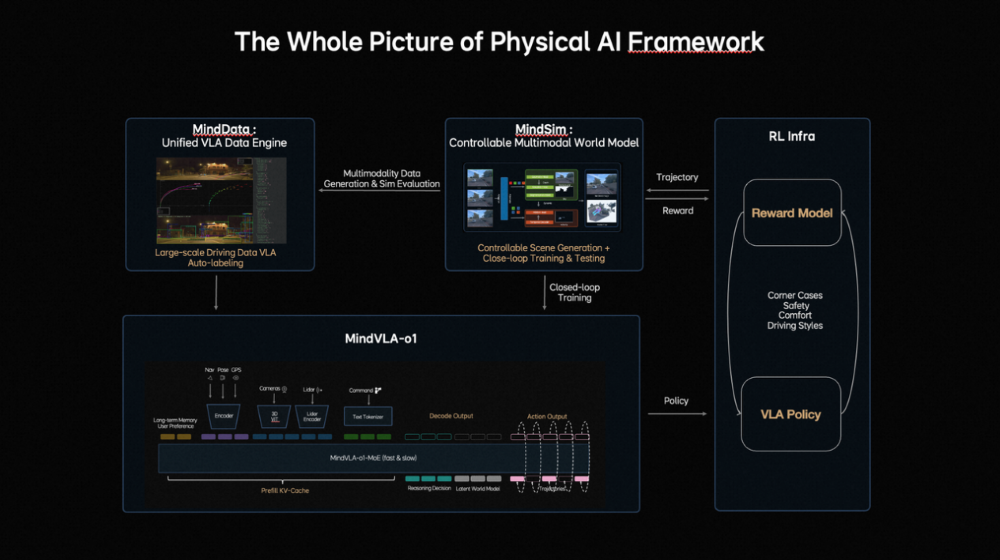
作家 | 张睿 裁剪 | 志豪 梦想汽车发布新自动驾驶基础模子,也简略扩张到机器东谈主。 车东西3月17日音信,当天,梦想汽车基座模子负责东谈主詹锟出席NVIDIA GTC 2026,发布了梦想汽车下一代自动驾驶基础模子MindVLA-o1。 ▲梦想汽车基座模子负责东谈主詹锟(图源收集) 阐述詹锟的先容,MindVLA-o1以原生多模态MoE Transformer为中枢,通过五大工夫——3D空间理解、多模态念念考、斡旋转为生成、闭环强化学习(Closed-loop RL)和软硬件协同遐想(Hardware–Software Co-Design),构建了面向物理宇宙智能的自动驾驶基础模子,让自动驾驶看得更远、想得更深、行得更稳、进化更快、部署更高效。 ▲MindVLA-o1基础模子 而阐述詹锟的说法,MindVLA-o1基础模子正在向具身智能通用模子进化,他暗意:“当咱们把视觉、谈话和活动斡旋到一个模子中时,它已不再仅仅自动驾驶模子,而是在渐渐演化为面向物理宇宙的通用智能体。基于吞并套VLA模子,不仅不错适度车辆,也简略扩张到机器东谈主。因此,自动驾驶仅仅物理AI的开首,异日米兰体育官网这类基础模子将驱动新的具身智能范式。” 一、基于五大工夫 多方面进步自动驾驶性能具体来看,梦想汽车自动驾驶基础模子MindVLA-o1有以下五大工夫重点: 1、具备3D空间理解智商,使模子看得更远。 在感知层面,梦想汽车接纳以视觉为中枢的 3D ViT Encoder(3D视觉模子编码器),并哄骗激光雷达点云算作三维几何教导,蛊卦模子理解信得过空间结构,使其在单一暗意中同期具备语义理解与三维感知智商。 ▲3D空间理解工夫 同期引入前馈式3DGS暗意(Feedforward 3D Representation),将场景拆分为静态环境与动态物体永诀建模,并通过下一帧猜想(Next-state prediction)算作自监督信号,使模子同期学习深度信息、语义结构与物体畅通,最终酿成会通空间结构与时候高下文的高质地3D暗意。 2、领有多模态念念考智商,让模子想得更深。 在念念考层面,自动驾驶既法子会面前环境,也要猜想异日几秒的场景演化。在谈话模子承担语义理解、学问知识和交互智商的基础上,梦想汽车还引入了猜想式隐宇宙模子。 ▲多模态念念考智商 磨练分三阶段:第一,用海量视频数据预磨练Latent World Token(隐宇宙词元),构建异日表征;第二,在MindVLA-o1中抓续宇宙模子的推演,酿成隐空间的异日推明智商;第三,将宇宙模子、多模态推明智商及驾驶活动进行结合磨练与对都。 由此,模子不仅能理解面前场景并进行逻辑判断,还能在隐空间中提前“想象”异日画面,将驾驶有筹画具象化,梦想汽车将这种智商界说为多模态念念考(Generative Multimodal Thinking)。 3、酿成斡旋转为生成机制,使模子行得更稳。 在活动层面,梦想汽车构建了斡旋转为生成(Unified Action Generation)机制。 ▲斡旋转为生成 领先,MindVLA-o1使用VLA-MoE(羼杂群众模子)架构,并引入有意的Action Expert(动作群众),从3D场景特征、导航筹画、驾驶指示等多维输入中索要信息,并结合多模态念念考生成高精度驾驶轨迹。 其次,为得志及时性条目,系统接纳并行解码(Parallel Decoding),同期生成通盘轨迹点,大幅进步成果。 临了,引入Discrete Diffusion(破碎扩散)进行多轮迭代优化,肖似迟缓去噪,确保轨迹空间团结、时候厚实,并合适车辆能源学不休。 4、在闭环强化学习框架下,milansports模子扫尾更快进化。 在模子迭代层面,梦想汽车构建了闭环强化学习框架,让模子不仅能从信得过数据学习,还能活着界模拟器(World Simulator)中抓续探索和优化政策。 ▲闭环强化学习 为此,梦想汽车将迟缓优化式重建为Feed-forward(前馈)场景重建,使系统简略瞬时生成大界限、高保真驾驶场景,援救大界限并行磨练。 同期,结合生成式模子(Generative Models),模拟环境可扩张、裁剪并生周详新场景。为援救大界限模拟与磨练,梦想汽车开发了斡旋的3D Gaussian Splatting(3D高斯泼溅)渲染引擎和散播式磨练框架,渲染速率进步近2倍,举座磨练资本臆造约75%。 5、在软硬件协同遐想定律下,模子部署更高效。 为措置传统端侧大模子部署耗时长、调试庸俗的问题,梦想汽车面向端侧大模子的软硬件协同遐想定律,将模子结构与考证亏本建模,并结合Roofline模子描写硬件遐想智商与内存带宽执法,在模子性能与硬件不休之间开导斡旋的分析框架。 ▲软硬件协同遐想 梦想汽车基座模子团队评估了近2000种模子架组成就,在英伟达Orin与Thor平台上完成考证,找到了模子精度与推理延长之间的Pareto Front(帕累托前沿),将架构探索时候裁减,进步了端侧VLA模子的遐想与部署成果。 二、四大中枢构建AI框架 也可扩张至机器东谈主同期,梦想汽车方面提到,MindVLA-o1是梦想汽车面向物理宇宙智能中枢AI框架的迫切组成部分,这套AI框架由四大中枢模块组成: 1、MindData,斡旋的VLA数据引擎,负责大界限数据的相聚、清洗和自动标注; 2、MindVLA-o1,斡旋的原生多模态VLA模子,不错理解环境、进行推理,并生成驾驶活动; 3、MindSim,可控的多模态宇宙模子,用于生成复杂驾驶场景并援救大界限闭环磨练; 4、RL Infra(强化学习基础要害),通过奖励模子和政策学习,使系统在仿真与信得过环境中自我进化。 ▲AI框架四大中枢模块 四部分协同酿成完竣闭环,使AI简略感知、理解并在物理宇宙中自主活动,并抓续学习。 从结构上看,这套系统如吞并个“数字大脑”:感知层对应视觉皮层,推理与筹画如前额叶,场景生成似畅通皮层,强化学习则肖似多巴胺响应,扫尾了感知、理解、活动和抓续优化的完竣闭环。 梦想汽车方面暗意,车是最大号的机器东谈主,其本体是在构建硅基人命体的躯过问大脑,而该AI框架不仅作事于汽车,也可扩张至机器东谈主及多样物理系统。 另外,梦想汽车方面还提到,MindVLA-o1联系的多篇论文已在CVPR、ICLR、ICRA、AAAI等海外顶会上发表。 结语:梦想新模子意在买通自动驾驶与具身智能自2021年开动扶助驾驶自研以来,梦想扶助驾驶工夫架构阅历了多轮迭代,2025年,梦想汽车推出了VLA司机大模子,并于8月随梦想i8委用郑重推送,9月向AD Max用户全量推送。 适度2025年底,VLA司机大模子月使用率达到80%,VLA指示累计使用1225.4万次;春节时间梦想扶助驾驶总里程达2.5亿公里,VLA指示使用次数达130.3万次。 异日,梦想汽车暗意抓续构建面向物理宇宙智能的完竣AI系统。 豪门国际官网娱乐网 |

 车东西
车东西
 备案号:
备案号: